반응형

이번에는 저번 글에 이어
전체 페이지 가져오기를 해보겠습니다.
일단 저번 글의 코드 밑에 이어서 작성하겠습니다.
변수 전달 중 pd 등 저번 코드에서 약속 해놓은걸 그대로 사용하니까요.
한가지 추가로 import 해줘야합니다.
저번 코드 import 부분에
import requests 를 추가해주시길 바랍니다.
그럼 이번에도 코드 작성 후 해석을 해보겠습니다.
#페이지 전체 읽기
df =pd.DataFrame()
#df변수가 pandas 모듈의 데이터 프레임형임을 알립니다.
sise_url ='https://finance.naver.com/item/sise_day.nhn?code=068270'
for page in range(1, int(last_page)+1):'
#저번에 구해준 마지막 페이지, last_page를 정수형으로 자료형을 고정해준 후,
#마지막 페이지 수보다 하나 큰 페이지에 도달할 때까지 아래 코드를 반복해주라는 코드입니다.
url = '{}&page={}'.format(sise_url, page)
#for문에서 전달받은 page(for문이 반복될 때마다 계속 1씩 증가한다)와
#맨 위에서 선언한 url을 {},{} 사이에 format함수를 이용하여 넣는다.
html =requests.get(url, headers={'User-agent' : 'Mozila/5.0'}).text
df = df.append(pd.read_html(html, header=0)[0])
#해당 페이지를 함수를 이용해 읽은 후 df에 객체로 저장해줍니다.
df =df.dropna()
#df 객체에서 dropna함수를 이용하여 값이 빠진 행을 제거해줍니다.......입니다만 실행이 안됩니다.
저번 글에서와 같은 문제인것 같습니다.
네이버에서 웹스크롤 제한을 걸어 유저의 정보를 전달해주지 않으면 데이터를 보내주지 않는것 같네요.
다른 분들의 블로그를 참고하여 수정해봤습니다.
https://bonghanwith.tistory.com/192 이분 블로그에 상세하게 나와있습니다.
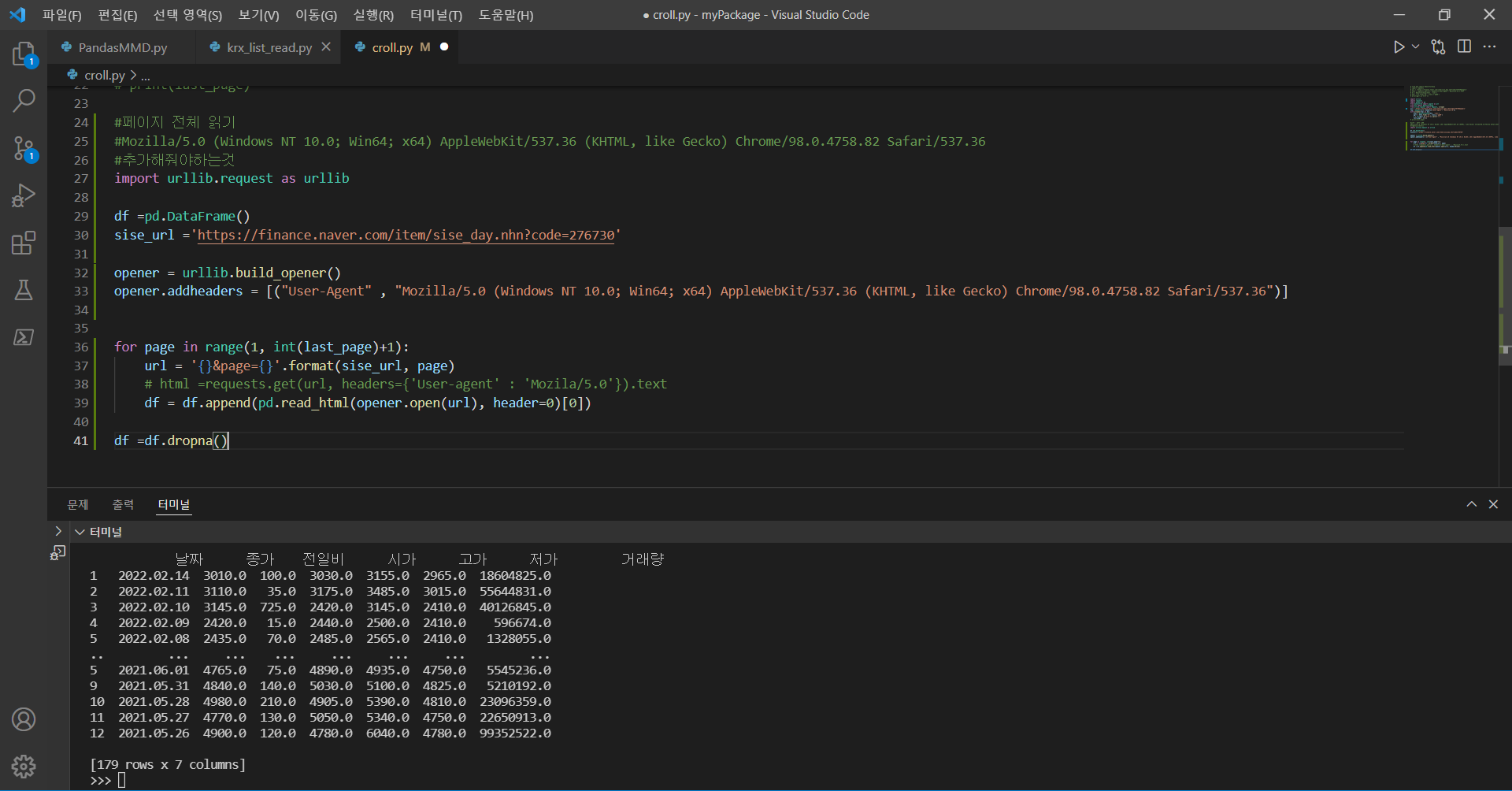
#페이지 전체 읽기
#Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36
#추가해줘야하는것
import urllib.request as urllib
df =pd.DataFrame()
sise_url ='https://finance.naver.com/item/sise_day.nhn?code=276730'
opener = urllib.build_opener()
opener.addheaders = [("User-Agent" , "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36")]
for page in range(1, int(last_page)+1):
url = '{}&page={}'.format(sise_url, page)
# html =requests.get(url, headers={'User-agent' : 'Mozila/5.0'}).text
df = df.append(pd.read_html(opener.open(url), header=0)[0])
df = df.dropna()
마지막에 print(df) 를 입력해주면 결과가 나옵니다.
반응형
'코딩 공부 > python' 카테고리의 다른 글
| 각 사이트의 주식 데이터 비교하기 (야후 파이낸스의 문제점??) (0) | 2022.02.16 |
|---|---|
| 제주맥주 종가 차트 파이썬으로 그려보기 (0) | 2022.02.16 |
| Python으로 웹 데이터 스크래핑하기 (0) | 2022.02.11 |
| Pandas 를 이용한 주식 수익률 구하기 (2) | 2022.02.10 |
| Pandas 공부 중 새로운 오류 경험 (0) | 2022.02.10 |




댓글